米兰app官方网站 RAG新SOTA, 还在5亿条数据上跑进秒级, 只好它了


裁剪|Sia
前阵子,Claude Code 无意泄露了 512,000 行 TypeScript 源码。
好家伙,Anthropic 这波莫不是把 Claude Code 的「底裤」王人露出来了?
AI 圈扒完之后发现,最有酷爱的地点不是模子,而是 Claude Code 这个 Coding Agent 外面那层运行系统。
泄露的大部分代码,王人在处理这些事:什么时候读文献,什么时候调用器具,什么时候压缩高下文,什么时候不绝下一步。
也即是今天越来越火的 Agent Harness。

一次无意,也算给行业提了个醒。
Agent 时间,果然病笃的不仅仅模子才能,还有模子外面那套高下文组织、器具调用和任务轮回系统。

这套系统里,勾通「模子」和「外部常识寰宇」的基础身手——RAG,也必须随着进化。
为啥嘞?

如若有东说念主想知说念「某条居品阶梯到底受谁影响?」,谜底可能藏在这样一条链里:
A 公司收购了 B 公司、B 公司的 CTO 自后加入了 C 技俩、 C 技俩又影响了某条居品阶梯。
三件事分开看,巧合王人和用户的问题相配相似;只好把它们串起来,才是果然的谜底。
传统 RAG 不错赶快在费事库里找到几段「看起来最像」的文本,但巧合拧得清它们之间是啥关系。
对 Agent 来说,这就很要命。
因为, Agent 不仅仅问答,它还要基于检索成果不绝推理、调用器具、作念下一步决策。第一步检索错了,背面就会一齐跑偏。
成果会有多离谱呢?
有商酌发现,在医学临床文本生成中,传统 RAG 时期反而让大模子幻觉率,从基线气象的 5.0% 飙升至 43.6%。
原因即是,它仅仅找到了「看起来关联」的费事,而不是循证的凭证。

这亦然为什么,it’s time to 从头想考 RAG。
不预则废?Graph 也不是银弹啊
以微软 GraphRAG 为代表的决议,算是对传统 RAG 局限的一次病笃修正。
如故上头阿谁问题:某条居品阶梯到底受谁影响?
GraphRAG 会先把 A 公司、B 公司、CTO、C 技俩、居品阶梯这些实体,以及它们之间的关系抽出来,作念成一张常识图谱。
再沿着「谁和谁策动」、「哪些事件属于归拢个主题」、「哪些信息共同指向一个论断」去组织谜底。
这一步很病笃。它让 RAG 检朴单的向量相似度匹配,向结构化关系推理迈出了一大步。
尤其是在全局相识和主题总结上,GraphRAG 确乎很管用。

引入常识图谱像是给 RAG 修了一座常识宫殿,漂亮也更有结构,但构建和爱戴起来却不胜重担。
抽三元组、合并实体、归一关系、建全局图、作念社区摘抄……每一步王人很贵,每一步王人可能出错。
更无语的是,好拒绝易盖好了,一朝果然查询时,许多系统并莫得充分「沿着图里的关系去找谜底」,临了如故反璧到「找几个相似节点 / 相似摘抄」老一套。
最要命的是,寰宇总在变。今天技俩负责东说念主换了、来日客户需求变了、后天某条居品阶梯又被推翻了……
预制的图谱,总不成每天推倒重建吧?

不久之后,另一条强阶梯 HippoRAG 2 登场了。
受海马体记念启发,它但愿系统像东说念主脑回忆一样:从一个陈迹开赴,沿着图里的关系扩散,激活更多关策动念。
如若用户想知说念,某条居品阶梯到底受谁影响?
HippoRAG 2 会先识别环节实体和陈迹,比如 A 公司、B 公司、CTO。然后在图谱里激活相要津点。
接着用 Personalized PageRank 这类图排序算法,沿着关系不绝扩散:从 B 公司找到 CTO、张三、 C 技俩,直到居品阶梯。临了,再把这些陈迹交给LLM 生成谜底。
通过把 RAG 不绝推向「结构化记念」和「多跳检索」,HippoRAG 2 确乎有用措置了传统 RAG 在多跳推理和永恒记念上的一部分问题。
但也相似留住了雄伟的工程挑战。

和 GraphRAG 一样,HippoRAG 2 也离不开一张离线构建的全局图。
况兼,查询时还要在 graph 上跑 PageRank / Personalized PageRank 这类排序算法。
这套递次在 benchmark 限度下很强,一朝到了果然 Agent 场景,全局图的爱戴和排序就会变得很重。
脑补一下:每天王人要合手续写入新文档、新实体、新笔名、新关系......
那有莫得一种办法:
既要结构,又不要一上来就修一座常识宫殿;
既要多跳,又不要每次王人在全局图上跑一遍复杂排序;
既要扶植 Agent 永恒使用,又不成每来一批新数据,就把整张图推倒重建;
……
面前,轮到广州智跃深空东说念主工智能科技有限公司 Zleap AI 提倡的 SAG(SQL-Retrieval Augmented Generation) 出场了。
SAG:用超边结构重构 Agent 数据底座
其实,名字依然点题了——不是 Graph、Hippo,而是 SQL-Retrieval。
它的中枢想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕现时问题,用 SQL 动态串出一张局部陈迹网。
举例,开运体育中国app官方手机版一些盘问《给阿嬷的情书》的原始 chunk 如下。



传统三元组会把这段完整事件链,拆成许多条 「主体 - 关系 – 客体」:
侨批 — 具有 — 家信属性
侨批 — 具有 — 汇款凭证属性
深圳企业 — 投资 — 《给阿嬷的情书》
影片 — 使用 — 方言
但一段话时常不是一个粗浅关系,而是一件完整的事。强行拆成许多三元组,就像把一篇新闻剪成碎纸条,关系词抽错少量,整条陈迹就断了。
SAG 改成:

也即是说,一个 chunk 对应一个完整的 event。一个 event 不错勾通多个 entity。
反过来,一个 entity 也可能出面前多个 event 里。

一个 event,把多个 entities 绑在了沿途,在图结构上,这更像「超边(many-to-many hyperedge)」。
这些王人会被写进 SQL 和向量索引里。查询时,系统通过分享实体把关联事项临时连起来。

SAG结构表现图,离线写入。
当用户想知说念,为什么会有东说念主投资《给阿嬷的情书》?
SAG 会先让 LLM 从查询中识别实体,比如投资方、深圳企业、资金起原、投资决策。然后,兵分两路。
第一条路,是结构旅途。
系统会去 SQL 中查询:哪些事项卡和这些实体策动?它可能领先找到「深圳企业投资《给阿嬷的情书》」这张事项卡( event )。
这张卡能讲授投资方看中了影片的社会传播和阛阓扩散后劲,但还不成完整回复「为什么值得投」。
于是,SAG 会不绝读取 event 里的 entities。举例:深圳企业、潮汕、侨乡经济、华情面感、家庭不雅影、社会传播,再通过 SQL 反查其他包含这些 entities 的 event 。
这样,系统会进一步找到「侨批题材带来文化价值」这张卡( event );再沿着侨批、地域文化、国外华东说念主、内行文化价值等 entities,找到「主创造就和中小本钱制作缩短投资风险」这张卡( event ) 。
通盘这个词流程实质上是 SQL join,不是全局图推理。最终,本来漫衍在不同 chunk 里的信息被串成一条链。
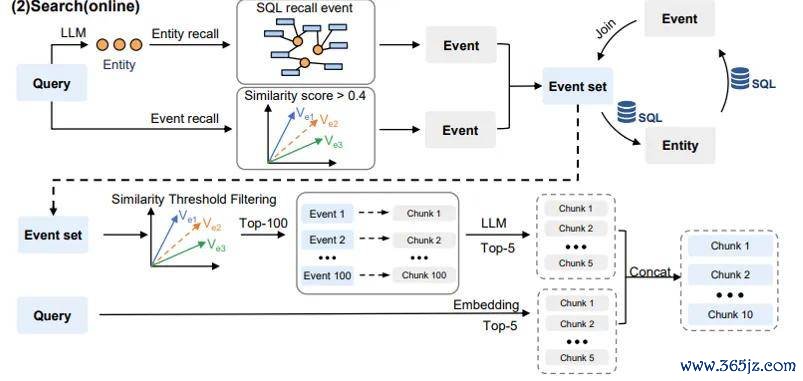
SAG结构表现图,在线检索。
第二条路,是语义旅途。
SAG 也不会完全铲除传统向量检索,它会同期用 query 的 embedding,径直去 chunk 索引里找语义上最相似的文本。
是以,SAG 临了拿到其实是两批候选。
系统此时会作念一轮相似渡过滤,再让 LLM 在更小的候选集里挑出最环节的 event。
临了,再把这些 event 映射回原始 chunk,和径直向量调回的 chunk 合并,酿成最终给 LLM 看的凭证。
临了你赢得的谜底,可能是这样:
投资东说念主之是以欢畅投资《给阿嬷的情书》,并不是因为它一启动就具备传统生意大片的外不雅。相悖,这个技俩名义上有不少风险,米兰app官方网站比如方言抒发、非流量演员、弱生意类型。但也有几个上风,投资东说念主投《给阿嬷的情书》,实质上是在投一个文化辨识度强、本钱风险可控、厚谊共识有扩散后劲的电影技俩。
RAG 新 SOTA 到了
说了这样多,SAG 到底有莫得用? Zleap AI 拿了三个经典多跳问答数据集来测:
HotpotQA、2WikiMultiHopQA、MuSiQue。
它们王人在考系统会不会「寻讲究底」。尤其是 MuSiQue,最多要作念 4 跳推理,基本即是 RAG 里的硬骨头。
敌手 HippoRAG 2 ,也饱胀不是软柿子。
成果,在调节成就下:
SAG 的平均 Recall@2 / Recall@5 达到:79.3% / 88.2%。
HippoRAG 2 是:68.2% / 83.3%。
SAG 在前 2 条成果里掷中环节凭证的能力,径直跨越了 11.1 个百分点。越早掷中,背面的 token 越省,延长越低,推理链也越拒绝易跑偏。
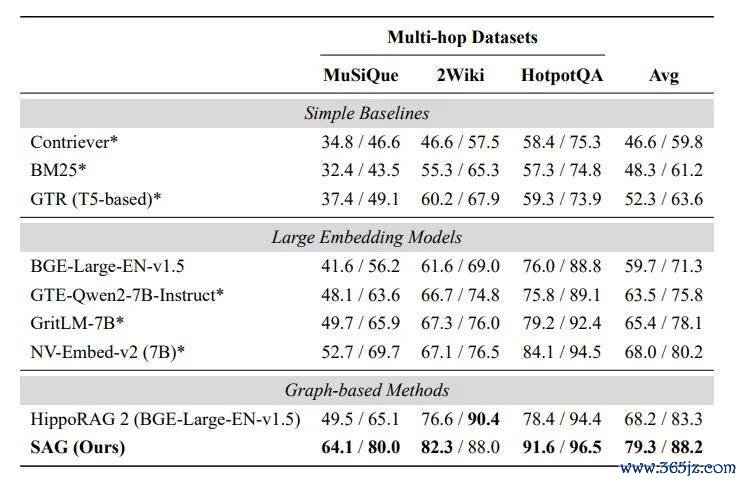
最难的 MuSiQue,也很能讲明问题。
SAG 的 Recall@5 是 80.0%,HippoRAG 2 是 65.1%,差了快要 15 个百分点。
可见,在越需要多跳推理的场景里,SAG 的「事项 + 实体 + SQL 膨大」越能阐扬作用。
消融现实进一步扶植了提高来自结构自己的判断。
MuSiQue测试集,三元组版 SAG 的 Recall@5 是 77.1%,超边版是 80.0%;
关闭查询时膨大后,Recall@5 从 80.0% 降到 69.4%;
用轻量 reranker 替代 Qwen3.6-Flash 作念最终采选,Recall@5 从 80.0% 降到 62.2%。
论文还考据了 SAG 对 embedding 模子不解锐。
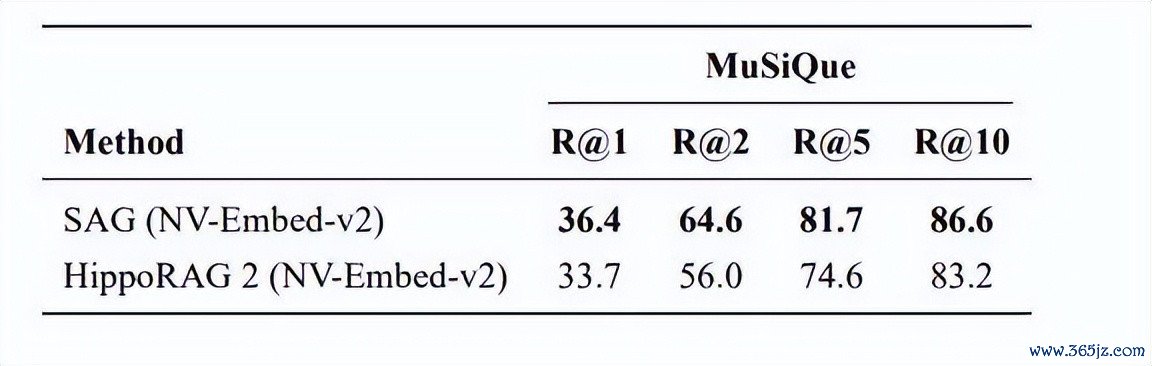
换成更强的 NV-Embed-v2 后:
SAG 在 MuSiQue 上 Recall@5 从 80.0% 到 81.7%,变化不大。
HippoRAG 2 对 embedding 更明锐,从 BGE 成就下的 65.1% 到 NV-Embed-v2 下的 74.6%。
果然起作用的,是底层结构变了,而不是堆更强 embedding 。
新 SOTA,还能工业落地,也就它了
据 Zleap AI 泄露,SAG 依然在约 5 亿条数据限度的分娩环境中部署,且数据限度还在合手续增长,在线检索延长保合手在秒级以内。
刷新 SOTA,还能如斯限度化落地的 RAG,揣测也就 SAG 了。

SAG 能在大限度数据下防守低延长,环节在于单干。
慢活儿,离线作念。用 LLM 作念结构化抽取,把 chunk 变成 event 和entity;
欣慰儿,在线作念。用 SQL、向量索引和全文索引快速调回。只让 LLM 判断很小的候选集。
SAG 也比 GraphRAG 更扛增长。
因为,chunk 是自然的并发单位,每个 chunk 王人不错孤独处理。
每当新网页、新文档、新技俩进来,无用从头瞎想全局关系,径直把新增内容变成新的 event 和 entity 并入索引体系即可。
它不是一张每天王人要重修的常识图谱,更像一套能合手续滋长的陈迹档案库,这使得增量处理和合手续膨大,王人成了我方的上风。
固然,许多东说念主会问实体越来越多,合并会不会很复杂?
会复杂,但 SAG 莫得把「无缺实体合并」放在主链路里。这点也和 GraphRAG 很不一样。
GraphRAG 把实体当成图里的中枢节点,实体合并错了,整张图王人会被混浊。不对并,旅途又会断掉。是以,必须持重作念实体消歧,工程量也会越来越大。
但 SAG 不错继承一定进度的「不无缺合并」。
因为 entity 不是谜底自己,更像是「路标」;event 才是那张写明晰事情经过的卡片。
比如,归拢家公司被写成几个不同名字,系统不一定要在入库时坐窝判断它们是不是归拢个实体。
SAG 不错先保守处理:入库前作念粗浅字符串归一和 SQL 查询,在归拢个 source 下,如若同类型、同名字的实体依然存在,就径直复用。莫得,就插入为新实体。
后续查询时,再通过向量检索、全文检索和 LLM 重排把关联陈迹补回首。
为了让用户更直不雅地体验这套机制,Zleap AI 还作念了一个 Wikipedia 搜索 demo。咱们也粗浅问了个问题:
与《给阿嫲的情书》主题相似的电影,还有哪些呢?
很快,它就放出一段基于十几条成果的总结。底下是被调回的凭证卡片,比如《亲爱的奶奶》、《阿嬷的梦中情东说念主》、《情书》。

体验地址:https://wiki.zleap.com/search
点开《亲爱的奶奶》,右侧还能看到这条成果为什么被调回,以及它对应的原始凭证。

左边复返了《亲爱的奶奶》《阿嬷的梦中情东说念主》《情书》这些成果,而是右边展示了每条成果为什么被调回。
这即是 SAG 的可追究性。Agent 不仅仅要拿到谜底,还要知说念谜底从哪来;不仅仅要回复现时问题,还要知说念下一步该沿着哪条陈迹不绝查。
最有酷爱的是 View Graph。

它不是一张提前建好的常识图谱,而是 SAG 针对这一次问题,临时张开的一张局部陈迹网。
图里的节点,即是系统围绕现时问题调回出来的一批事项卡( event )。用户问亲情电影,系统就围绕亲情、书信、家庭、回忆这些陈迹膨大
如若问「收购 Instagram 的公司,其创举东说念主上过哪所大学」,系统又会围绕 Instagram、Facebook、创举东说念主、大学这些实体和关系从头膨大。
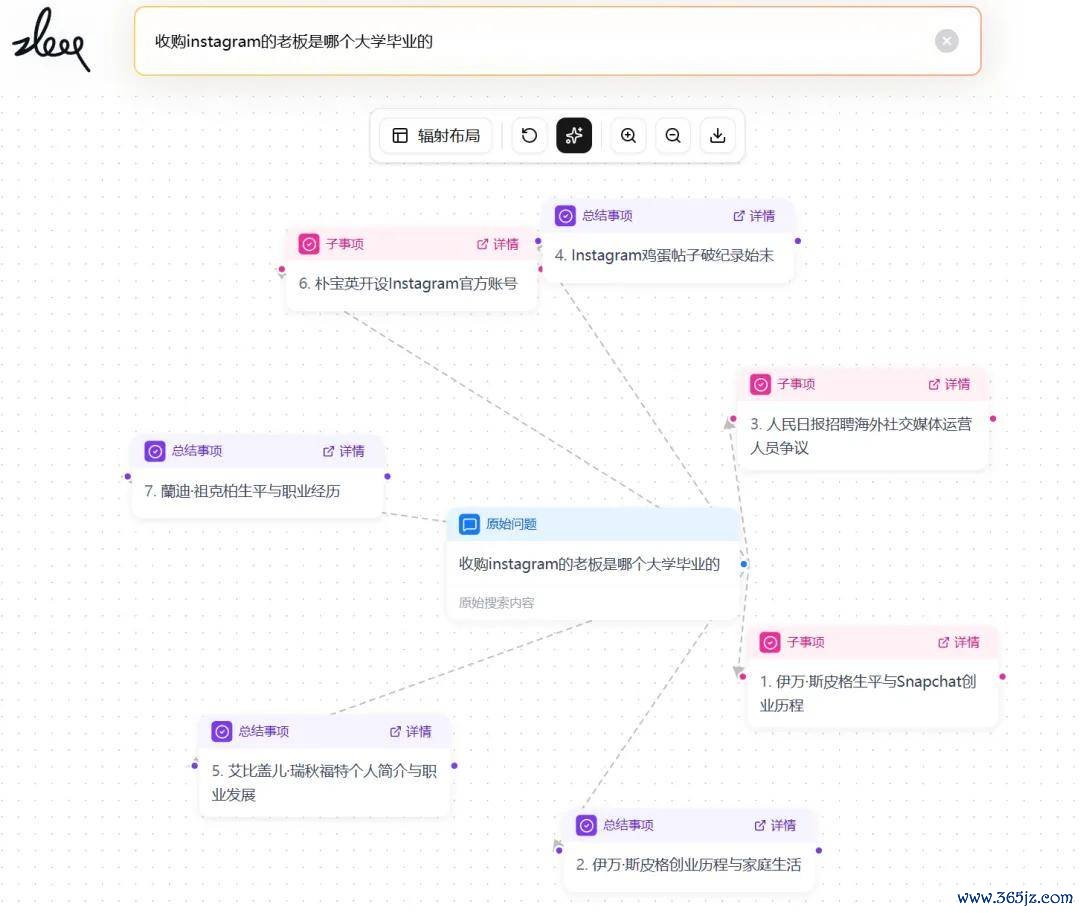
也即是说,SAG 不是提前把全寰宇的关系王人算好,再等用户来查。它是在问题发生时,只激活现时问题需要的局部关系。
这恰是它能合适大限度 RAG、并与传统 RAG、GraphRAG 拉开差距的环节。
不啻是常识,还有记念
对 Agent 来说,果然的数据底座,其实还要能承载记念。
除了知说念外部寰宇发生了什么,Agent 还需要知说念:用户偏好什么抒发方法,某个技俩鼓舞到了哪一步,上一次任务查到了什么论断,哪个旧判断自后又被新信息推翻。
这些内容如若只按日常 RAG 的方法存成文本块,系统就只可找回一段相似聊天记载,却巧合知说念哪条是历史配景,哪条是现时气象,哪条依然失效。
SAG 刚好提供了一个更当然的组织方法。
每条记念王人不错被写成一个 event:谁,在什么时候,对什么对象,作念了什么事,产生了什么气象变化;关联的东说念主、技俩、任务、偏好,可行为 entity 勾通起来。
这样一来,Agent 的记念就不再是一堆松散的历史对话,而是一套不错合手续写入、按陈迹找回、随问题动态张开的事项档案。
固然,论文也提到,果然面向永恒 Agent Memory,还需要进一步加入版块化和时期感知能力。但这亦然它行为 Agent 数据底座最值得期待的地点。
从这个角度看,SAG 果然指向的是一种新的数据组织范式:常识不错被合手续写入,记念不错被沿陈迹找回,气象变化也有契机被永恒跟踪。
这概况亦然下一代 Agent 数据基座果然需要补上的一课。
参考聚首
1、开源技俩地址:
https://github.com/Zleap-AI/SAG
2、论文地址:
https://arxiv.org/abs/2606.15971
3、策动医疗AI幻觉的论文:
2026世界杯中国线上平台Representation Before Retrieval: Structured Patient Artifacts Reduce Hallucination in Clinical AI Systems米兰app官方网站